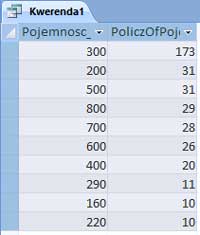
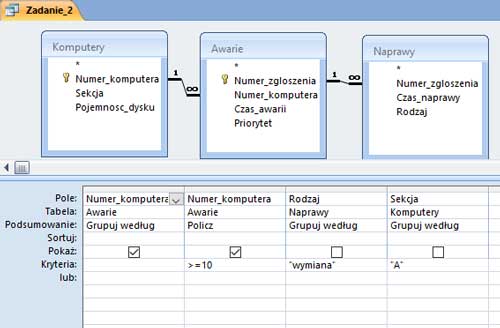
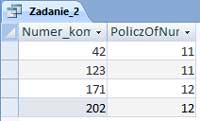
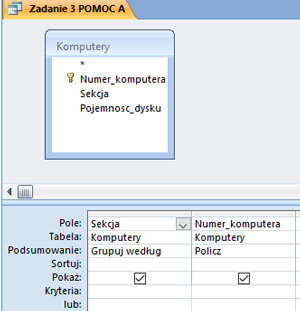
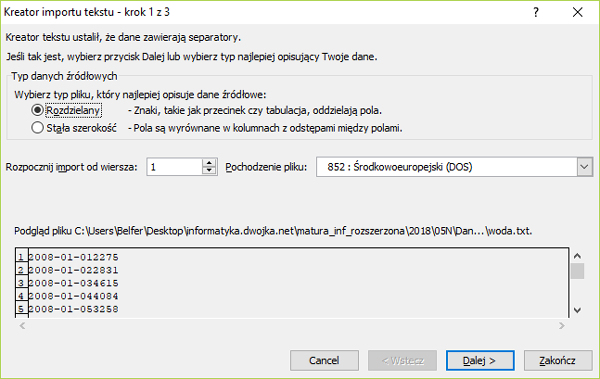
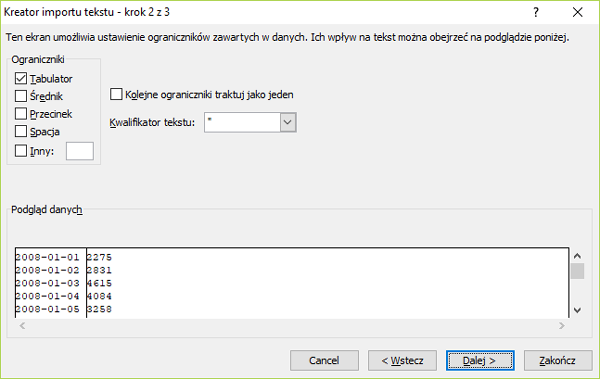
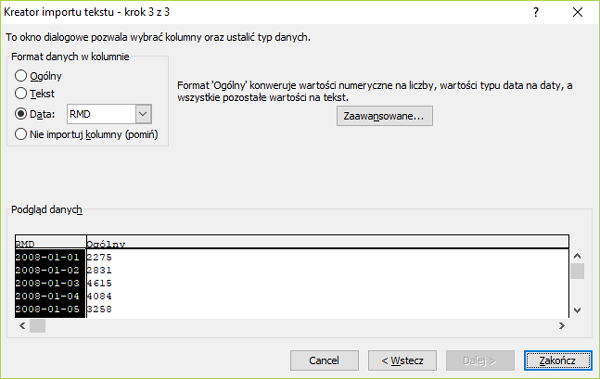
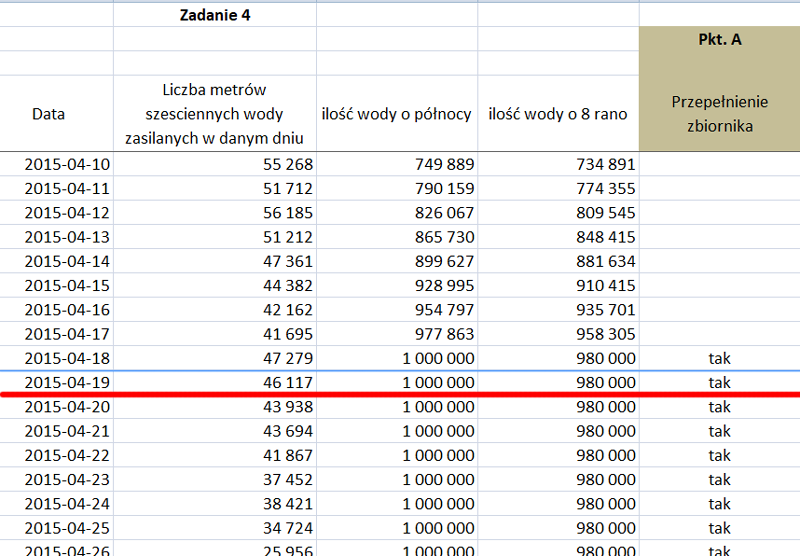
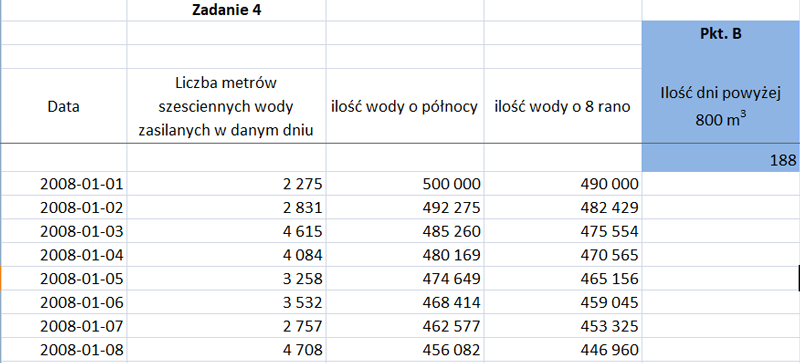
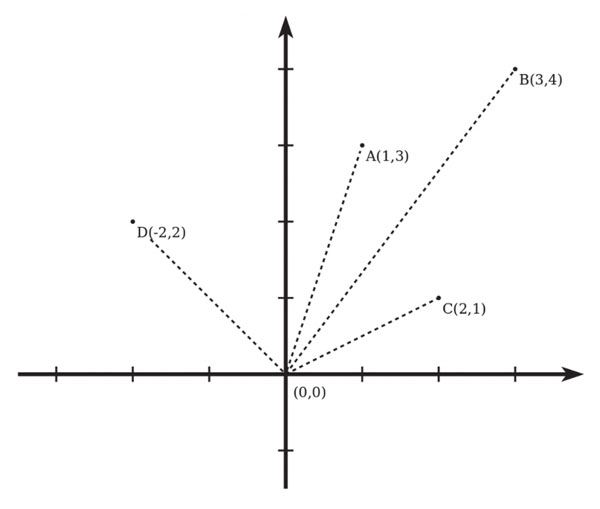
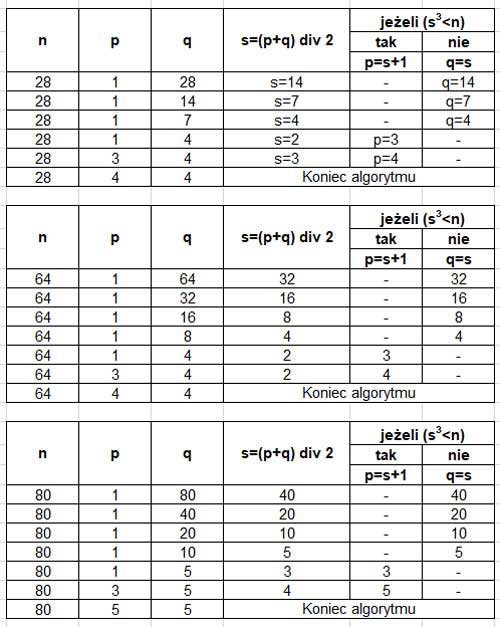
Matura 2015 (maj). Zadanie 1. Problem telewidza
W Problemie telewidza mamy program telewizyjny, zawierający listę filmów emitowanych w różnych stacjach telewizyjnych jednego dnia. Telewidz zamierza obejrzeć jak najwięcej filmów w całości. Jedyne ograniczenie jest takie, że telewidz może oglądać co najwyżej jeden film (stację telewizyjną) jednocześnie. Zakładamy, że jednego dnia wszystkie filmy są różne.
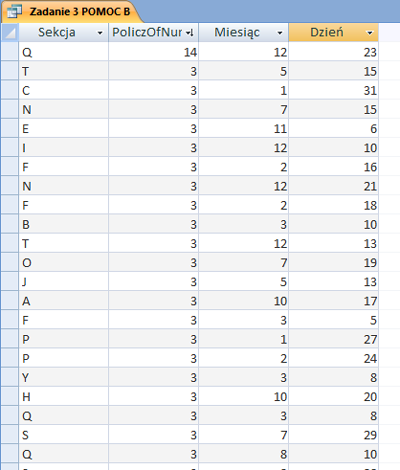
Program telewizyjny emisji filmów w 4 stacjach telewizyjnych:
| Telewizja / stacja | Film i godziny jego emisji | Czas trwania emisji filmu |
| TV1 | film 1: od 9:00 do 12:00 film 2: od 15:00 do 17:00 |
3 godziny 2 godziny |
| TV2 | film 3: od 11:00 do 16:00 | 5 godzin |
| TV3 | film 4: od 12:00 do 14:00 | 2 godziny |
| TV4 | film 5: od 11:30 do 12:30 | 1 godzina |
Dla programu podanego powyżej telewidz jest w stanie obejrzeć aż trzy filmy, np.: film 1, film 4, film 2. Przyjmujemy, że telewidz nie traci w ogóle czasu na przełączanie pomiędzy stacjami (np. o godz. 12:00 z TV1 na TV3). Innymi słowy, czasy emisji filmów 1 i 4 nie kolidują ze sobą.
Rozważ następujący algorytm wyboru filmów do obejrzenia przez telewidza, w którym w kroku 2. stosuje się jedną z czterech strategii opisanych w tabeli 1.
Specyfikacja:
Dane:
T – zbiór filmów z programu telewizyjnego z godzinami emisji i czasami ich trwania,
S – strategia z tabeli 1.
Wynik:
P – zbiór filmów, które obejrzy telewidz.
Algorytm:
Krok 1. Zainicjuj P jako zbiór pusty.
Krok 2. Dopóki T zawiera jakieś filmy, wykonuj:
– stosując strategię S, wybierz ze zbioru T film x i usuń go z T
– dodaj film x do zbioru P
– usuń ze zbioru T wszystkie filmy, których czasy emisji kolidują z czasem emisji filmu x.
Krok 3. Zakończ wykonywanie algorytmu i wypisz wszystkie filmy ze zbioru P.
Tabela 1. Cztery strategie (S) w Problemie telewidza:
| Strategia A | Wybierz film, który trwa najdłużej, a jeśli jest takich więcej, to wybierz z nich ten, który się najwcześniej kończy. Jeśli jest więcej takich filmów,wybierz dowolny z nich. |
| Strategia B | Wybierz film, który trwa najkrócej, a jeśli jest takich więcej, to wybierz z nich ten, który się najwcześniej kończy. Jeśli jest więcej takich filmów, wybierz dowolny z nich. |
| Strategia C | Wybierz film, który się najwcześniej zaczyna, a jeśli jest takich więcej, to wybierz z nich ten, który się najwcześniej kończy. Jeśli jest więcej takich filmów, wybierz dowolny z nich. |
| Strategia D | Wybierz film, który się najwcześniej kończy, a jeśli jest takich więcej, to wybierz z nich ten, który się najpóźniej zaczyna. Jeśli jest więcej takich filmów, wybierz dowolny z nich. |
Przykład:
Dla podanego programu telewizyjnego zastosowanie w kroku 2. strategii A daje wynik P = {film 3}, czyli telewidz obejrzy tylko jeden film.
Zadanie 1.
Dla podanego programu telewizyjnego podaj wyniki wykonywania algorytmu po zastosowaniu strategii B, C i D:
| Strategia S | Zawartość zbioru P po zakończeniu wykonywania algorytmu |
| B | P = {film 5, film 2} |
| C | P = {film 1, film 4, film 2} |
| D | P = {film 1, film 4, film 2} |
Zadanie 2.
Zastosowana strategia S w algorytmie jest optymalna, jeśli dla każdego programu telewizyjnego wynik algorytmu (zbiór P) zawiera największą możliwą liczbę filmów, które może obejrzeć telewidz.
Uwaga:
Strategia A nie jest optymalna, ponieważ telewidz może obejrzeć trzy filmy: film 1, film 4 oraz film 2.
Dla strategii A, B i C podaj w przygotowanych tabelach przykłady programów telewizyjnych, z emisją czterech filmów w dwóch stacjach, będące dowodami, że żadna z tych strategii nie jest optymalna.
Dla każdej strategii i podanego dla niej programu telewizyjnego podaj wynik działania algorytmu oraz przykład ilustrujący, że telewidz może obejrzeć więcej filmów, jeżeli nie używa tej strategii.
Wskazówka. Podaj takie godziny emisji czterech filmów, aby telewidz był w stanie obejrzeć np. trzy lub więcej filmów, podczas gdy zastosowanie algorytmu z odpowiednią strategią daje rozwiązanie zawierające co najwyżej dwa filmy.
Dowód dla strategii A:
| Telewizja / stacja | Film i godziny jego emisji | Czas trwania emisji filmu |
| TV1 | film 1 (od …………………. do ………………….), film 2 (od …………………. do ………………….) |
…………………. …………………. |
| TV2 | film 3 (od …………………. do ………………….), film 4 (od …………………. do ………………….) |
…………………. …………………. |
Wynik działania algorytmu przy zastosowaniu strategii A:
| P |
Liczniejszy zbiór filmów, które może obejrzeć widz:
| Z |
Dowód dla strategii B:
| Telewizja / stacja | Film i godziny jego emisji | Czas trwania emisji filmu |
| TV1 | film 1 (od …………………. do ………………….), film 2 (od …………………. do ………………….) |
…………………. …………………. |
| TV2 | film 3 (od …………………. do ………………….), film 4 (od …………………. do ………………….) |
…………………. …………………. |
Wynik działania algorytmu przy zastosowaniu strategii B:
| P |
Liczniejszy zbiór filmów, które może obejrzeć widz:
| Z |
Dowód dla strategii C:
| Telewizja / stacja | Film i godziny jego emisji | Czas trwania emisji filmu |
| TV1 | film 1 (od …………………. do ………………….), film 2 (od …………………. do ………………….) |
…………………. …………………. |
| TV2 | film 3 (od …………………. do ………………….), film 4 (od …………………. do ………………….) |
…………………. …………………. |
Wynik działania algorytmu przy zastosowaniu strategii C:
| P |
Liczniejszy zbiór filmów, które może obejrzeć widz:
| Z |